[ad_1]
This is not the most straight forward post request, if you look in developer tools or firebug you can see the formdata from a successful browser post:
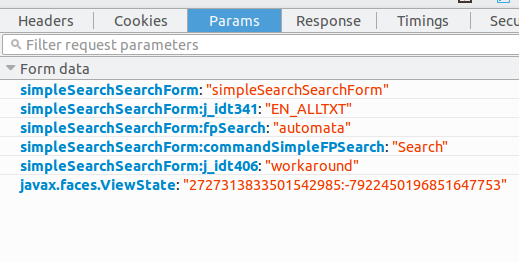
All that is pretty straight forward bar the fact you see some : embedded in the keys which may be a bit confusing, simpleSearchSearchForm:commandSimpleFPSearch is the key and Search.
The only thing that you cannot hard code is javax.faces.ViewState, we need to make a request to the site and then parse that value which we can do with BeautifulSoup:
import requests
from bs4 import BeautifulSoup
url = "https://patentscope.wipo.int/search/en/search.jsf"
data = {"simpleSearchSearchForm": "simpleSearchSearchForm",
"simpleSearchSearchForm:j_idt341": "EN_ALLTXT",
"simpleSearchSearchForm:fpSearch": "automata",
"simpleSearchSearchForm:commandSimpleFPSearch": "Search",
"simpleSearchSearchForm:j_idt406": "workaround"}
head = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.75 Safari/537.36"}
with requests.Session() as s:
# Get the cookies and the source to parse the Viewstate token
init = s.get(url)
soup = BeautifulSoup(init.text, "lxml")
val = soup.select_one("#j_id1:javax.faces.ViewState:0")["value"]
# update post data dict
data["javax.faces.ViewState"] = val
r = s.post(url, data=data, headers=head)
print(r.text)
If we run the code above:
In [13]: import requests
In [14]: from bs4 import BeautifulSoup
In [15]: url = "https://patentscope.wipo.int/search/en/search.jsf"
In [16]: data = {"simpleSearchSearchForm": "simpleSearchSearchForm",
....: "simpleSearchSearchForm:j_idt341": "EN_ALLTXT",
....: "simpleSearchSearchForm:fpSearch": "automata",
....: "simpleSearchSearchForm:commandSimpleFPSearch": "Search",
....: "simpleSearchSearchForm:j_idt406": "workaround"}
In [17]: head = {
....: "User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.75 Safari/537.36"}
In [18]: with requests.Session() as s:
....: init = s.get(url)
....: soup = BeautifulSoup(init.text, "lxml")
....: val = soup.select_one("#j_id1:javax.faces.ViewState:0")["value"]
....: data["javax.faces.ViewState"] = val
....: r = s.post(url, data=data, headers=head)
....: print("\n".join([s.text.strip() for s in BeautifulSoup(r.text,"lxml").select("span.trans-section")]))
....:
Fuzzy genetic learning automata classifier
Fuzzy genetic learning automata classifier
FINITE AUTOMATA MANAGER
CELLULAR AUTOMATA MUSIC GENERATOR
CELLULAR AUTOMATA MUSIC GENERATOR
ANALOG LOGIC AUTOMATA
Incremental automata verification
Cellular automata music generator
Analog logic automata
Symbolic finite automata
You will see it matches the webpage. If you want to scrape sites you need to get familiar with developer tools/firebug etc.. to watch how the requests are made and then try to mimic. To get firebug open, right click on the page and select inspect element, click the network tab and submit your request. You just have to select the requests from the list then select whatever tab you want info on i.e params for out post request:

You may also find this answer useful on how to approach posting to a site.
1
[ad_2]
solved Python urllib2 or requests post method [duplicate]