[ad_1]
The following script will create result.csv based on your original sample data (see past edits to question):
import csv
from collections import defaultdict
d_entries = defaultdict(list)
with open('fileTwo.csv', 'r') as f_fileTwo:
csv_fileTwo = csv.reader(f_fileTwo)
header_fileTwo = next(csv_fileTwo)
for cols in csv_fileTwo:
d_entries[(cols[0], cols[1])].append([cols[0], ''] + cols[1:])
with open('fileOne.csv', 'r') as f_fileOne, open('result.csv', 'w', newline="") as f_result:
csv_fileOne = csv.reader(f_fileOne)
csv_result = csv.writer(f_result)
header_fileOne = next(csv_fileOne)
csv_result.writerow(header_fileOne)
for cols in csv_fileOne:
if (cols[0], cols[2]) in d_entries:
csv_result.writerow(cols)
csv_result.writerows(d_entries.pop((cols[0], cols[2])))
result.csv will then contain the following data when opened in Excel:
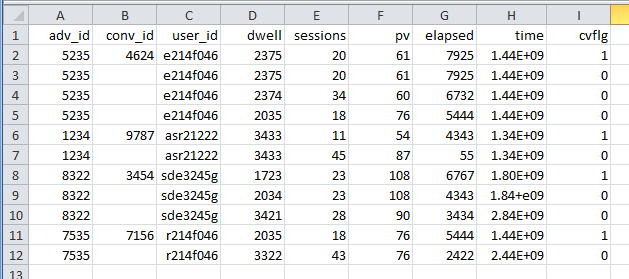
Tested in Python 3.4.3
To only match on the adv_id columns and to have all entries:
import csv
from collections import defaultdict
d_entries = defaultdict(list)
with open('fileTwo.csv', 'r') as f_fileTwo:
csv_fileTwo = csv.reader(f_fileTwo)
header_fileTwo = next(csv_fileTwo)
for cols in csv_fileTwo:
d_entries[cols[0]].append([cols[0], ''] + cols[1:])
with open('fileOne.csv', 'r') as f_fileOne, open('result.csv', 'w', newline="") as f_result:
csv_fileOne = csv.reader(f_fileOne)
csv_result = csv.writer(f_result)
header_fileOne = next(csv_fileOne)
csv_result.writerow(header_fileOne)
for cols in csv_fileOne:
if cols[0] in d_entries:
csv_result.writerows(d_entries.pop(cols[0]))
csv_result.writerow(cols)
19
[ad_2]
solved How to merge two CSV files by Python based on the common information in both files?