[ad_1]
CONCLUSION – 07-25-2021
After looking at this problem in more detail, I believe that it is NOT technically possible to use Python Requests to scrape the website and table in your question.
Which means that your question cannot be solved in the manner that you would prefer.
Why?
The website employs anti-scraping mechanisms.
The GBK values are only one part of these mechanisms. The table that you’re trying to scrape has 1504 pages. A new unique GBK value is created each time you navigate from page 1 to the next page and so forth. Thus there are 1503 unique GBK value.
The site also uses a unique session management cookie for each page.
# page 1 cookie
JSESSIONID=0AC56294FE6857A236F0E68A9106E1AE.7; neCYtZEjo8GmS=5El51n08q7nzOG_bzzqhGWyfW_Lx9tCv1uZA6QjBcUq0rH0d1XYIvTKzN3MfNn2cZasqfZoM8Yo5NTpuq9gM.IG; neCYtZEjo8GmT=53HTPEbke3aQqqqm_6QLwIaUKu0tMygss.En464jhvNz1mMzbOatzmLLtv9x_xiCP6JaO_JzcbvHqtsnQYydBa6B_YjSg6sFm7cVBBOhB35_.TZuwDsbOnDinJkNwMs3AaMPtM83dP9YnogFKHpNJo5.RHMTKT6_XNPr0mxebR6stRrQ7LFfACcWqHHhbc.j6gZfZzxsgwnPE3RGP6aT9nYuMJbvK2EGrdAv0O12G03KTk_BMk.xLeEwrQq5VjyH1tB7t4wQ.jQ1geshvbDPCs8_VHCkd2.6uIag5Md.lngzeDshhSjMrmBjyy0HTqAXQ3; acw_tc=276aedd816272186939626726e424a5dd554d4b095225e2cac90fc6d2da583
# page 2 cookie
JSESSIONID=651AD12FD349FFB1842E08CA578EA37D.7; neCYtZEjo8GmS=5El51n08q7nzOG_bzzqhGWyfW_Lx9tCv1uZA6QjBcUq0rH0d1XYIvTKzN3MfNn2cZasqfZoM8Yo5NTpuq9gM.IG; neCYtZEjo8GmT=53HTPeKke3e7qqqm_6Q_YEqK9dBPNnJQF00YvHDMLHlJeb.4rrpTsgfwZxU0S5OXIAB2aduoOTmj7RuKIL.LUXRaRqfh5ZByuTFX3LxK1Ia3sr3V45c.PPx6Eas5EF5EkQztquzrX78QIbjrJUcQoKoOKcqgX5UuRIN0gCyGDyI6FFj.JbPhwYf65Hcx9BzDQnrlGAPHM3WGvmKf7OJnLY1SGIuxtdyVUE359Ll2lr0QJxUq1Dacqz_WsFa_ZantBbP7MklHX6J21wmDnyo6s4xCeeTYwsGq.kGUbE74Dx.QjQBCM_SiLKccTog8_EdBDg; acw_tc=276aedd816272186939626726e424a5dd554d4b095225e2cac90fc6d2da583
# page 3 cookie
JSESSIONID=2121D74E0EFCEC3BE104DAA2791481B6.7; neCYtZEjo8GmS=5El51n08q7nzOG_bzzqhGWyfW_Lx9tCv1uZA6QjBcUq0rH0d1XYIvTKzN3MfNn2cZasqfZoM8Yo5NTpuq9gM.IG; neCYtZEjo8GmT=53HTPeKke3e7qqqm_6wBfEGBZsTF9_uGtgepzPXNOzFh0RNtGcE1Cf4hEQNppVywcI5mk3SlLkzvNll6ovr4XmfL2Ujy3AFZR5leVY2H3_584At3GmIwmnsEjOx5v5e_lMon3AbX9t2W8UiLoK.9SBX0vgNRfkqdpyPjWKk3Zs8gQG0k3_6UwxGTvEwWkaWL8vquJgCGlvLEFTjNvd07eHiR482UfpLPFP6yAkx8Wi9pM79cL.26KE3U2L79hgBKLHyOdNyj3VKOkDsaXefNdPXd.YqT4kevShGxzMM2PuzqnuuQnW.GQ5mr9Rx8VxUjEa; acw_tc=276aedd816272186939626726e424a5dd554d4b095225e2cac90fc6d2da583
So you would need to acquire both the unique GBK value and the unique session management cookie for each page between 2 and 1504.
I also noted that site employs some type of latency. The first page can take some time to fully load. If you attempt to navigate to another page before this page load is complete you will get this message “请勿频繁操作!”
It’s worth nothing that some pages took up to 2 minutes to load. When they didn’t load the message above was displayed.
Like I previously mentioned you should consider scraping this site with selenium, which might work to bypass the anti-scraping mechanisms.
UPDATE POST (SELENIUM)- 07-27-2021
I have attempted to scrape your target website with selenium. The chromedriver continually fails to connect to the site. Even if these switches are used:
chrome_options.add_experimental_option("useAutomationExtension", False)
chrome_options.add_experimental_option("excludeSwitches", ['enable-automation'])
chrome_options.add_argument("--disable-blink-features=AutomationControlled")
I also tried using the undetected-chromedriver, but that also failed to property connect.
Even when I set a high timeout period with either driver.set_page_load_timeout() or driver.implicitly_wait() the session still fails with chromedriver.
I was able to access the website when I used selenium with the geckodriver. There are still time out issues, but adding a WebDriverWait couple with an expected_conditions seems to overcome some of the timeout issues.
Scraping this website will be a long and arduous process, because of the anti-scraping mechanisms being used.
ORIGINAL POST – 07-24-2021
First let me say, that your question doesn’t have enough details to make a solid recommendation for solving your issue.
I looked into your problem. I found that your target website uses some Javascript to dynamically create the GBK value that is used each post request.
6SQk6G2z:GBK-5lkb7acLMDDxywZsCHoJagJlT50f1gw4.jaVgaBpBcGZDs1T_pcR_OPFgvOm_6oM8PfyL3L6xDPxFqgIqgwbVAEw8y4jd0P5yTWo3dx1cNLnCOYTa4mVr7azAXa9YiDEhOz7M1Qsw6BJIOSq0QVp.Ng.NWri7ByAK6dwme99ZEOnjraxZex1xLVGakyVVCoOEhFGfphV8D1GDFKLt1dG.4_XuCPDIoLNGmy4Dzd92SxlNWCQ707A8tvqP7jQq2wyRBV0M3y0moSs8I03rIXeYNKE3AkMmI8Xp4M6GZd0seJqGvGrN7vA8lJbiBfmEgtcSvPZF0hrfkVRvQGq9uHRx9JOLtdkujsYHk6TW7rYBVsQ

This GBK value is used when navigating between the pages 1 through 1504. I noted that the value changes for each page.

import difflib
# page 2
a = "6SQk6G2z:GBK-5lkb7acLMDDxywZsCHoJagJlT50f1gw4.jaVgaBpBcGZDs1T_pcR_OPFgvOm_6oM8PfyL3L6xDPxFqgIqgwbVAEw8y4jd0P5yTWo3dx1cNLnCOYTa4mVr7azAXa9YiDEhOz7M1Qsw6BJIOSq0QVp.Ng.NWri7ByAK6dwme99ZEOnjraxZex1xLVGakyVVCoOEhFGfphV8D1GDFKLt1dG.4_XuCPDIoLNGmy4Dzd92SxlNWCQ707A8tvqP7jQq2wyRBV0M3y0moSs8I03rIXeYNKE3AkMmI8Xp4M6GZd0seJqGvGrN7vA8lJbiBfmEgtcSvPZF0hrfkVRvQGq9uHRx9JOLtdkujsYHk6TW7rYBVsQ"
# page 1504
b = "6SQk6G2z:GBK-59tY9cXfYPiYfpgB1rj16jFZNwQuke.NUV5ZljqD6daOH4pxgaFcRE7bERjrvfoY4OTl5PAWUo70VNRIqnYOi_TQCSWzvrcCgfTtEFl_ZdMHRVLhosJLSFwHiPdVn4cXZ7VnF5xahstqJHD6EBfd71iZT8HQBmx1dssd7RWA2Gdv8lGhJbS0ZeaxIVkfK5qaO.lxHVvG_9cq4weBdHeUQlGlIWhxKFYePkTr9Jp0eN2yDTZljeX0XWWOxIjEkdj89FOqaNDB2slUE.54oC96baGe7lttoz_2AoTbjHSTjfDh.eSyT6vA6.5dP5X.4XsFVYSnYKIznIdkjTURmm3kjvGM_iQoYT3V5gAKs1c6r6cE"
s = difflib.SequenceMatcher(None, a, b, autojunk=False)
for tag, i1, i2, j1, j2 in s.get_opcodes():
if tag != 'equal':
print('{:7} a[{}:{}] --> b[{}:{}] {!r:>8} --> {!r}'.format(
tag, i1, i2, j1, j2, a[i1:i2], b[j1:j2]))
# output
insert a[14:14] --> b[14:49] '' --> '9tY9cXfYPiYfpgB1rj16jFZNwQuke.NUV5Z'
replace a[15:18] --> b[50:55] 'kb7' --> 'jqD6d'
replace a[19:24] --> b[56:60] 'cLMDD' --> 'OH4p'
delete a[25:49] --> b[61:61] 'ywZsCHoJagJlT50f1gw4.jaV' --> ''
insert a[51:51] --> b[63:158] '' --> 'FcRE7bERjrvfoY4OTl5PAWUo70VNRIqnYOi_TQCSWzvrcCgfTtEFl_ZdMHRVLhosJLSFwHiPdVn4cXZ7VnF5xahstqJHD6E'
insert a[52:52] --> b[159:243] '' --> 'fd71iZT8HQBmx1dssd7RWA2Gdv8lGhJbS0ZeaxIVkfK5qaO.lxHVvG_9cq4weBdHeUQlGlIWhxKFYePkTr9J'
insert a[53:53] --> b[244:276] '' --> '0eN2yDTZljeX0XWWOxIjEkdj89FOqaND'
replace a[54:55] --> b[277:291] 'c' --> '2slUE.54oC96ba'
replace a[56:57] --> b[292:311] 'Z' --> 'e7lttoz_2AoTbjHSTjf'
insert a[58:58] --> b[312:369] '' --> 'h.eSyT6vA6.5dP5X.4XsFVYSnYKIznIdkjTURmm3kjvGM_iQoYT3V5gAK'
delete a[60:63] --> b[371:371] 'T_p' --> ''
delete a[64:74] --> b[372:372] 'R_OPFgvOm_' --> ''
replace a[75:84] --> b[373:374] 'oM8PfyL3L' --> 'r'
replace a[85:99] --> b[375:376] 'xDPxFqgIqgwbVA' --> 'c'
delete a[100:377] --> b[377:377] 'w8y4jd0P5yTWo3dx1cNLnCOYTa4mVr7azAXa9YiDEhOz7M1Qsw6BJIOSq0QVp.Ng.NWri7ByAK6dwme99ZEOnjraxZex1xLVGakyVVCoOEhFGfphV8D1GDFKLt1dG.4_XuCPDIoLNGmy4Dzd92SxlNWCQ707A8tvqP7jQq2wyRBV0M3y0moSs8I03rIXeYNKE3AkMmI8Xp4M6GZd0seJqGvGrN7vA8lJbiBfmEgtcSvPZF0hrfkVRvQGq9uHRx9JOLtdkujsYHk6TW7rYBVsQ' --> ''
The GBK value is created with this call in the HTML of the page.
javascript:commitForECMA(callbackC,"content.jsp?tableId=27&tableName=TABLE27&tableView=杩涘彛鍖荤枟鍣ㄦ浜у搧锛堟敞鍐?&Id=60456",null)
This is the Javascript that is called.
function commitForECMA($_17, $_12, $_19) {
request = createXMLHttp();
request.onreadystatechange = $_17;
if ($_19 == null) {
_$b6(request, _$JI('ZM6r2MG'), _$JI("Op0YV"), $_12);
request.setRequestHeader(_$JI("RACeXwDYXwcTV8Ur2"), _$JI("9wDYgwceLwDT7iCYX3Ce9FKyvHKwPFa"));
} else {
var $_16 = "";
var $_11 = $_19.elements;
var $_14 = $_11.length;
for (var $_4 = 0; $_4 < $_14; $_4++) {
var $_6 = _$kH($_11, $_4);
if ($_6.type != _$JI("aQ6YPMK20") && _$kH($_6, _$JI('Cwbm7wKV')) != "") {
if ($_16.length > 0) {
$_16 += "&" + $_6.name + "=" + _$kH($_6, _$JI('swbm7wKV'));
} else {
$_16 += $_6.name + "=" + _$kH($_6, _$JI('8wbm7wKV'));
}
$_16 += _$JI("xx2J03Up2Hsl");
}
}
_$b6(request, _$JI('iM6r2MG'), _$JI("IVlesYq"), $_12);
$_16 = encodeURI($_16);
$_16 = encodeURI($_16);
request.setRequestHeader(_$JI("53CmOFDVz3CeXwoxBMq"), _$JI("wMbZz3CmOFDV"));
request.setRequestHeader(_$JI("ZACeXwDYXwcTV8Ur2"), _$JI("F3UraMD2O3UpNMCgB8cT6w6QzRbenM1TTQbS2MbJBRDY9"));
}
request.send($_16);
if ($_19 != null) {
$_19.reset();
}
}
truncated....
function createXMLHttp() {
if (window.XMLHttpRequest) {
return new XMLHttpRequest();
} else if (window.ActiveXObject) {
var $_17 = [_$JI("5sYJ3sVanh2fJslf0woqXJ1ga"), _$JI("osYJ3sVanh2fJslf0woqXJcga"), _$JI("ZsYJ3sVanh2fJslf0woqXWnga"), _$JI("fsYJ3sVanh2fJslf0woq"), _$JI("3sK2OQbeuMCR0h2fJslf0woq")];
for (var $_16 = 0; $_16 < $_17.length; $_16++) {
try {
return new ActiveXObject(_$kH($_17, $_16));
} catch ($_19) {}
}
throw new Error("您的浏览器不支持访问此网页");
}
}
truncated....
function callback() {
if (request.readyState == 1) {
_$_J(document.getElementById(_$JI("x3CeXwDYXwq")), '=', _$JI('3FKyXRUxEYlTW'), _$JI("EHDxnHOaB3vE5HDxnHOSNMKQGQ6xOHK2z3Kw2Qne7MCm9FKyvhbwNROg"));
}
if (request.readyState == 4) {
if (request.status == 200) {
oldContent.length = 0;
oldContent[0] = request.responseText;
_$_J(document.getElementById(_$JI("H3CeXwDYXwq")), '=', _$JI('OFKyXRUxEYlTW'), request.responseText);
request = null;
} else {
_$_J(document.getElementById(_$JI("w3CeXwDYXwq")), '=', _$JI('eFKyXRUxEYlTW'), "<br><br><br><span style=font-size:x-large;color:#215add>请勿频繁操作!</span>");
}
}
}
I’m looking to see if it is possible to obtain the GBK value and pass it back via Python Requests in some way.
For instance this code gives me a Status code of 202.
import requests
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:89.0) Gecko/20100101 Firefox/89.0",
}
conn_timeout = 30
read_timeout = 60
timeouts = (conn_timeout, read_timeout)
url="http://app1.nmpa.gov.cn/data_nmpa/face3/base.jsp?tableId=27&tableName=TABLE27&title=%E8%BF%9B%E5%8F%A3%E5%8C%BB%E7%96%97%E5%99%A8%E6%A2%B0%E4%BA%A7%E5%93%81%EF%BC%88%E6%B3%A8%E5%86%8C&bcId=152904442584853439006654836900"
response = requests.get(url, headers=headers, timeout=timeouts)
print(response.status_code)
# output
202
print(response.cookies)
# output
<RequestsCookieJar[<Cookie acw_tc=3ccdc15616274084596245338e08543386ba17e301ed12362cb2860b0af57f for app1.nmpa.gov.cn/>, <Cookie neCYtZEjo8GmS=5oWYI0i1mRB70b.XyuRJwTdiW_WgqfsIoOM8LNI8nfdTGyX4kfKTl0TDpV5HSMj2KIpgl8ircG4c9uAz_u50UkG for app1.nmpa.gov.cn/>]>
for key, value in response.headers.items():
print(f'Key: {key} -- Value: {value}')
# output
Key: Date -- Value: Tue, 24 Jul 2021 17:54:19 GMT
Key: Content-Type -- Value: text/html; charset=utf-8
Key: Transfer-Encoding -- Value: chunked
Key: Connection -- Value: keep-alive
Key: Set-Cookie -- Value: acw_tc=3ccdc15616274084596245338e08543386ba17e301ed12362cb2860b0af57f;path=/;HttpOnly;Max-Age=1800, neCYtZEjo8GmS=5oWYI0i1mRB70b.XyuRJwTdiW_WgqfsIoOM8LNI8nfdTGyX4kfKTl0TDpV5HSMj2KIpgl8ircG4c9uAz_u50UkG; Path=/; expires=Fri, 25 Jul 2031 17:50:29 GMT; HttpOnly
Key: Server -- Value: ******
Key: Pragma -- Value: no-cache
Key: Cache-Control -- Value: no-store
Key: Expires -- Value: Tue, 24 Jul 2021 17:50:29 GMT
Receiving a status code of 202 is an issue when trying to access the website using Python Requests, because the request isn’t being fully processed before the connection closes.
202 Accepted
The request has been accepted for processing, but the processing has not been completed. The request might or might not eventually be acted upon, as it might be disallowed when processing actually takes place. There is no facility for re-sending a status code from an asynchronous operation such as this.
The 202 response is intentionally non-committal. Its purpose is to allow a server to accept a request for some other process (perhaps a batch-oriented process that is only run once per day) without requiring that the user agent’s connection to the server persist until the process is completed. The entity returned with this response SHOULD include an indication of the request’s current status and either a pointer to a status monitor or some estimate of when the user can expect the request to be fulfilled.
I noted in the browser I get these items.
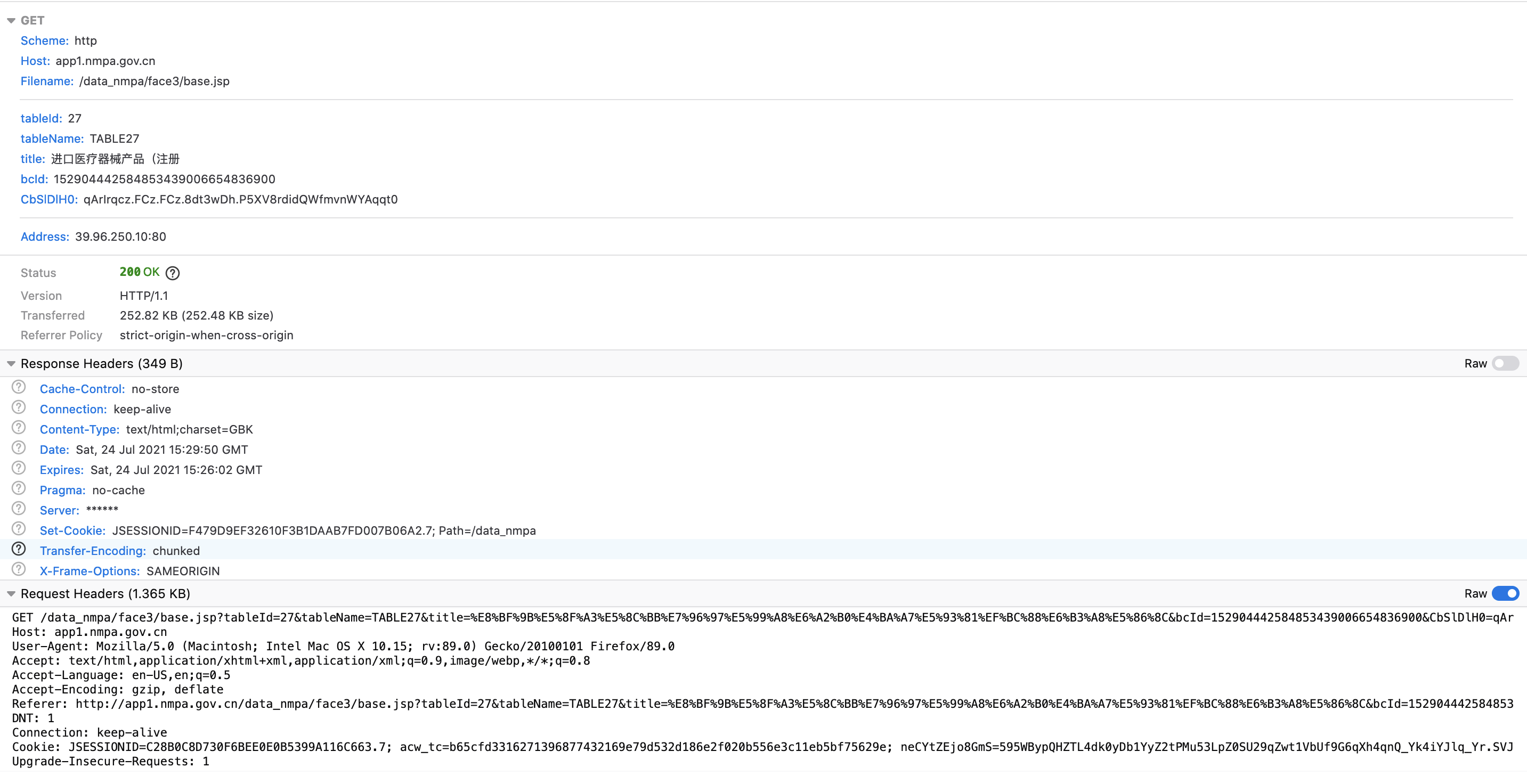
I’m still exploring how to pass these items in a Python Requests POST to get something useful back.
I haven’t looked at using selenium, but that Package seems to be the best option for extracting dynamically created content from this website in your question.
8
[ad_2]
solved Unable to communicate with API