[ad_1]
In cell I2, put the following formula (see UPDATE section for a simplified version):
=LET(setPrj, A2:E12, setRoster, A15:F33, SOMs, I1:T1,
namesPrj, INDEX(setPrj,,1), startsPrj, INDEX(setPrj,,4), endsPrj,
INDEX(setPrj,,5),names, INDEX(setRoster,,1),starts, INDEX(setRoster,,2),
ends, INDEX(setRoster,,3),
salaries,INDEX(setRoster,,6), empty, ",,",
SPLIT, LAMBDA(x,case, LET(y, TEXTSPLIT(TEXTJOIN(";",,x),",",";"), z,
FILTER(y, INDEX(y,,1)<>"", NA()),
IFS(case=0, z,case=1, HSTACK(INDEX(z,,1), 1*CHOOSECOLS(z,2,3)), case=2, 1*z))),
BYCOL(SOMs, LAMBDA(SOM, LET(EOM, EOMONTH(SOM,0),endsAdj, IF(ends > 0, ends, EOM),
overlapsPrj, MAP(namesPrj, startsPrj, endsPrj, LAMBDA(namePrj,startPrj,endPrj,
IF(AND(startPrj <= EOM, endPrj >= SOM),
TEXTJOIN(",",,namePrj, MAX(startPrj, SOM), MIN(endPrj, EOM)), empty))),
setPrjAdj, SPLIT(overlapsPrj,1),
overlapsRoster, IF(ISNA(ROWS(setPrjAdj)), NA(),
MAP(INDEX(setPrjAdj,,1), INDEX(setPrjAdj,,2), INDEX(setPrjAdj,,3),
LAMBDA(name,start,end,
LET(found, FILTER(HSTACK(starts, endsAdj, salaries), (names=name) * (starts <= end)
* (endsAdj >= start), NA()), IF(AND(ROWS(found)=1, NOT(ISNA(found))),
TEXTJOIN(",",, MAX(INDEX(found,,1), start),
MIN(INDEX(found,,2), end), INDEX(found,,3)), empty)
)))
),setRosterAdj, SPLIT(overlapsRoster,2),
IF(ISNA(ROWS(setRosterAdj)), 0,
LET(startEffDates, INDEX(setRosterAdj,,1), endEffDates, INDEX(setRosterAdj,,2),
effSalaries, INDEX(setRosterAdj,,3),days, NETWORKDAYS(startEffDates, endEffDates),
SUMPRODUCT(days, effSalaries)
))
)))
)
And here is the output in a single array 1x12 for the entire period.
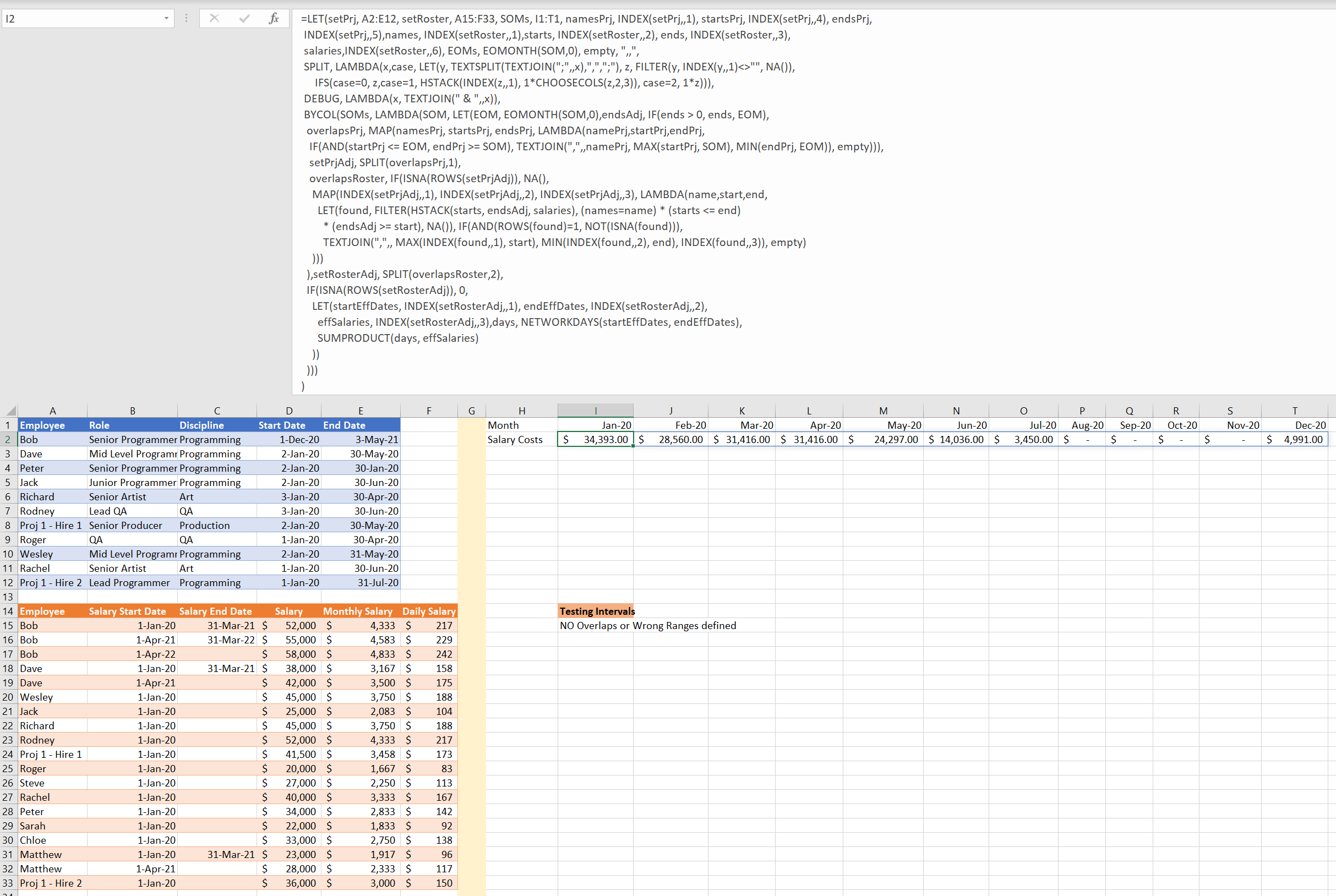
Note: In cell I15 I am using the idea suggested in the answer to the question: sequence a sumif with exclusions in Excel provided by me for checking that the intervals of the roster data set don’t overlap.
UPDATE
The formula can be simplified as follow. There is no need to define a user LAMBDA function: SPLIT. We can make the MAP function to return only the index position of the overlaps, and then use this information to find the rest of the information. We use also DROP/REDUCE/VSTACK/HSTACK combination to return multiple values (we were limited by MAP on returning only a single column)
=LET(setPrj, A2:E12, setRoster, A15:F33, SOMs, I1:T1,namesPrj, INDEX(setPrj,,1),
startsPrj, INDEX(setPrj,,4), endsPrj,INDEX(setPrj,,5),names, INDEX(setRoster,,1),
starts, INDEX(setRoster,,2), ends, INDEX(setRoster,,3), salaries,INDEX(setRoster,,6),
BYCOL(SOMs, LAMBDA(SOM, LET(EOM, EOMONTH(SOM, 0), endsAdj, IF(ends > 0, ends, EOM),
overlapsPrj, MAP(SEQUENCE(ROWS(setPrj)), startsPrj, endsPrj,
LAMBDA(idx, startPrj, endPrj,IF(AND(startPrj <= EOM, endPrj >= SOM),
idx, 0))), pIdx, FILTER(overlapsPrj, overlapsPrj > 0, NA()),
overlapsRoster, IF(ISNA(ROWS(pIdx)), NA(), DROP(REDUCE(0,pIdx,
LAMBDA(acc, idx, VSTACK(acc, LET(name, INDEX(namesPrj,idx),
start, MAX(INDEX(startsPrj,idx), SOM), end, MIN(INDEX(endsPrj,idx), EOM),
found, FILTER(HSTACK(starts, endsAdj, salaries), (names=name) * (starts <= end)
* (endsAdj >= start), NA()),
IF(AND(NOT(ISNA(found)), ROWS(found)=1), HSTACK(MAX(start, INDEX(found,1,1)),
MIN(end, INDEX(found,1,2)), INDEX(found,1,3)),{0,0,0})
)))),1)), rEff, FILTER(overlapsRoster, INDEX(overlapsRoster,,3) > 0, NA()),
IF(ISNA(ROWS(rEff)),0, LET(effStarts, INDEX(rEff,,1), effEnds,
INDEX(rEff,,2), effSalaries, INDEX(rEff,,3),days, NETWORKDAYS(effStarts, effEnds),
SUMPRODUCT(days, effSalaries)
)))))
)
Explanation
General Idea
For the calculation we use two main ideas:
The condition for checking if two intervals (
A,B) overlap:(StartA <= EndB) AND (EndA >= StartB) -> TRUEIf two intervals
A,Boverlap, the intersection of both intervals are:[MAX(StartA, StartB), MIN(EndA, EndB)]
We are going to iterate through each month. First look into the project dataset for interval overlaps on a given month, and for each interval that overlaps with the current month to find the intersection.
Once we have the list of resources with their corresponding intersections. We need to find the corresponding salary that matches the interval. We iterate again for the intersections found in the project dataset but now looking for a second intersection in the salary dataset.
Formula
We use LET function to define the inputs and intermediate results. We start defining two datasets setPrj for the data representing the project information and setRoster for the Roster information and related names required from the input set.
We are going to use MAP function (for finding each overlap) which is very convenient for doing transformations, it can take several input arrays of the same size, but then it returns a single array. To circumvent this, the output of MAP will be an nx1 array and on each row, the information will be a string with comma-separated values (CSV). We define inside of LET a user custom LAMBDA function to convert the result back from CSV format to a 2D array.
This user function is named SPLIT (don’t confuse it with TEXTSPLIT standard Excel function). Defining this function inside of LET function, the scope is limited to that function and there is no need to create a named range for that.
SPLIT, LAMBDA(x,case, LET(y, TEXTSPLIT(TEXTJOIN(";",,x),",",";"),
z, FILTER(y, INDEX(y,,1)<>"", NA()),
IFS(case=0, z,case=1, HSTACK(INDEX(z,,1),
1*CHOOSECOLS(z,2,3)), case=2, 1*z)))
Because the input argument x will be an nx1 array of comma-separated values, once we convert it to a 2D array, we need to convert some columns back to their original data type. We use the second input argument case, to consider all cast scenarios used in the main formula.
case=1, converts columns2and3to numberscase=2, converts all columns to numbers
Note: case=0, is not used in the main formula, provided for testing purposes only. The MAP output will be in both calls an array of three columns.
Finally, the output will be an nxm array that has been removed the empty rows (",,". There is a name defined for that: empty). In case all rows are empty, FILTER will return an error (the empty set doesn’t exist in Excel), to prevent that we use the third input argument of this function to return NA()(we use the same idea in other parts of the main formula)
Now we use BYCOL to iterate over the months (we use this function because the months are in column format). For each month (represented as the first day of the month) we use SOM(Start of the month) and EOM (End of the Month) names to find the overlaps and intersections. The first MAP call does it and the result is named intersecPrj:
MAP(namesPrj, startsPrj, endsPrj, LAMBDA(namePrj,startPrj,endPrj,
IF(AND(startPrj <= EOM, endPrj >= SOM),
TEXTJOIN(",",,namePrj, MAX(startPrj, SOM), MIN(endPrj, EOM)), empty)))
Note: Here we can use FILTER instead of MAP, but with the latter we can find the overlap and the intersection at the same time. The result is stored in CSV format by row with the following information: name, startDate, endDate where the dates represent the intersection dates.
Now we convert back the information to a 2D array via the SPLIT function: SPLIT(intersecPrj,1), because we want to keep the name as text we use case=1 and name it as: setPrjAdj it is an array nx3 where n represents the number of intersections found.
Now we need to find the corresponding salaries for the names in setPrjAdj. Here we need to consider the scenario where no intersection was found, i.e. for a given month, there are no projects with resources associated. The condition for calculating intersecRoster prevents that:
IF(ISNA(ROWS(setRosterAdj)), 0,…)
We can check against NA() because our SPLIT function returns this value in case of no intersections, so if the condition is TRUE we return NA(). If the input of ISNA is an array it returns an array, so we use ROWS to reduce the test to a single cell. If any element of the array has a #N/A value the ROWS output will be #N/A.
In case project intersections are found we need to find the salary and the corresponding new intersections between the date information in setPrjAdj and the dates in the roster dataset.
This is done via the following MAP call and name the result as intersecRoster
MAP(INDEX(setPrjAdj,,1), INDEX(setPrjAdj,,2), INDEX(setPrjAdj,,3),
LAMBDA(name, start, end,
LET(found, FILTER(HSTACK(starts, endsAdj, salaries), (names=name) * (starts <= end)
* (endsAdj >= start), NA()), IF(AND(ROWS(found)=1, NOT(ISNA(found))),
TEXTJOIN(",",, MAX(INDEX(found,,1), start),
MIN(INDEX(found,,2), end), INDEX(found,,3)), empty)
)))
For each name, start, and end (from setPrjAdj), HSTACK(starts, endsAdj, salaries) is filtered by name and look for overlaps.
It is used endsAdj, instead of ends original input data because we need to treat the blank end dates. The result is saved in the found name. Now we need to check for an empty set of the FILTER. The not found condition of the filter (empty set) is represented by the following output NA(). It could happen that the name was not found (some bad spelling or the name is missing).
In case it returns more than one row (it should not happen because the interval for the roster set should not overlap, i.e. an employee cannot have two salaries at the same time). We assign an empty row. There is no way to determine the salary, so this resource will not contribute to the Salary Monthly Cost. Otherwise, we build the string via TEXTJOIN with the corresponding information: start date, end dates, and the corresponding salary. Where the start and end dates represent the intersection between start and end dates (from setPrjAdj) and the start and end dates from the roster dataset (coming from the FILTER output).
Now intersecRoster has the following information in CSV format: start, end, salary. We do the same operation now to convert the string information into 2D-array, via SPLIT and name the result setRosterAdj. We use the case=2, because all the information is numbers.
SPLIT(intersecRoster,2)
Here we need to prevent the name was not found in the roster table, to avoid any unexpected result. In case no resource was found, then we return 0 via the following condition:
IF(ISNA(ROWS(setRosterAdj)), 0,…)
Now we have all the information we are looking for. For calculating the working dates we use NETWORKDAYS(startEffDates, endEffDates) where the dates are the corresponding columns from setRosterAdj and it is named as days.
Finally:
SUMPRODUCT(days, effSalaries)
Provides the result we are looking for. We named all the columns from setRosterAdj using Eff (effective) in the name of the corresponding column.
Monthly Salary for non-partial allocation
The previous approach calculates the cost based on working days and the daily salary. In case you will like to consider monthly cost instead for months when the resource was allocated the entire month and daily salary for partially allocated months, here is the adjusted formula:
=LET(setPrj, A2:E12, setRoster, A15:F33, SOMs, I1:T1, namesPrj, INDEX(setPrj,,1),
startsPrj, INDEX(setPrj,,4), endsPrj,INDEX(setPrj,,5),names, INDEX(setRoster,,1),
starts, INDEX(setRoster,,2), ends, INDEX(setRoster,,3),
monthlySalaries,INDEX(setRoster,,5), dalySalaries,INDEX(setRoster,,6), empty, ",,",
SPLIT, LAMBDA(x,case, LET(y, TEXTSPLIT(TEXTJOIN(";",,x),",",";"),
z, FILTER(y, INDEX(y,,1)<>"", NA()),IFS(case=0, z,case=1, HSTACK(INDEX(z,,1),
1*CHOOSECOLS(z,2,3)), case=2, 1*z))),
BYCOL(SOMs, LAMBDA(SOM, LET(EOM, EOMONTH(SOM,0),endsAdj, IF(ends > 0, ends, EOM),
overlapsPrj, MAP(namesPrj, startsPrj, endsPrj, LAMBDA(namePrj,startPrj,endPrj,
IF(AND(startPrj <= EOM, endPrj >= SOM), TEXTJOIN(",",,namePrj, MAX(startPrj, SOM),
MIN(endPrj, EOM)), empty))),
setPrjAdj, SPLIT(overlapsPrj,1),
overlapsRoster, IF(ISNA(ROWS(setPrjAdj)), NA(),
MAP(INDEX(setPrjAdj,,1), INDEX(setPrjAdj,,2), INDEX(setPrjAdj,,3),
LAMBDA(name,start,end,
LET(found, FILTER(HSTACK(starts, endsAdj, dalySalaries, monthlySalaries),
(names=name) * (starts <= end) * (endsAdj >= start), NA()),
IF(AND(ROWS(found)=1, NOT(ISNA(found))),
TEXTJOIN(",",, MAX(INDEX(found,,1), start), MIN(INDEX(found,,2), end),
CHOOSECOLS(found,3,4)), empty)
)))
),setRosterAdj, SPLIT(overlapsRoster,2),
IF(ISNA(ROWS(setRosterAdj)), 0,
LET(startEffDates, INDEX(setRosterAdj,,1), endEffDates, INDEX(setRosterAdj,,2),
effDailySalaries, INDEX(setRosterAdj,,3), effMonthlySalaries, INDEX(setRosterAdj,,4),
days, NETWORKDAYS(startEffDates, endEffDates), monthWorkDays, NETWORKDAYS(SOM, EOM),
actualSalaries, IF(days = monthWorkDays, effMonthlySalaries, effDailySalaries),
actualDays, IF(days = monthWorkDays, 1, days),
SUMPRODUCT(actualDays, actualSalaries)
))
)))
)
Tip
Since it is a large formula, and Excel doesn’t provide a way to debug properly some array functions, it is helpful to have a way to debug some of the partial results. Because BYCOL returns a cell per column, it is convenient to define another user’s LAMBDA function for this purpose inside of the LET. For example the following one and name it DEBUG.
LAMBDA(x, TEXTJOIN(" & ",,x)),
then it can be used to return the output of DEBUG instead of the final result for testing purposes.
0
[ad_2]
solved Calculating partial months salary costings for employees on a project in Excel [closed]